
Dissecting-Transformers: Understanding in-depth and using it for Neural Machine Translation task
Tech: Vanilla Transformer, Pre-trained Language Models, Neural Machine Translation, Pytorch, Python, HuggingFace, Streamlit, Docker
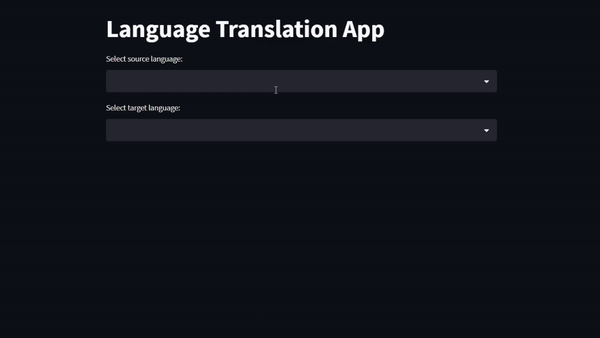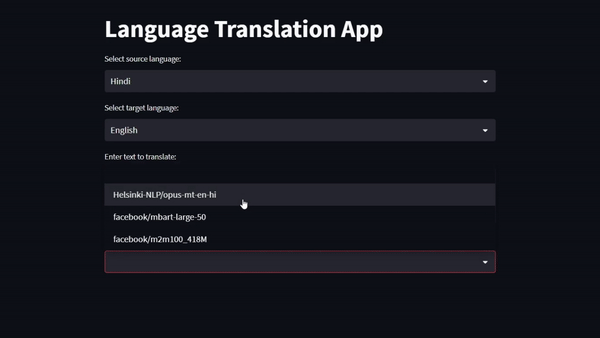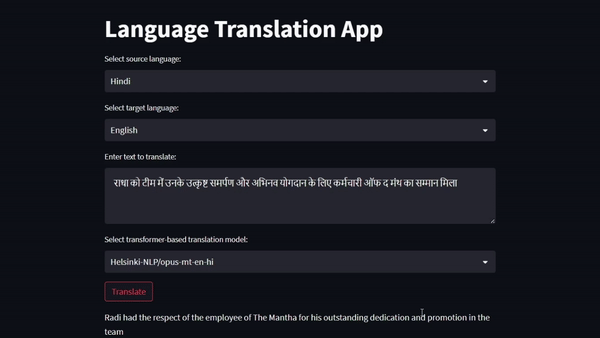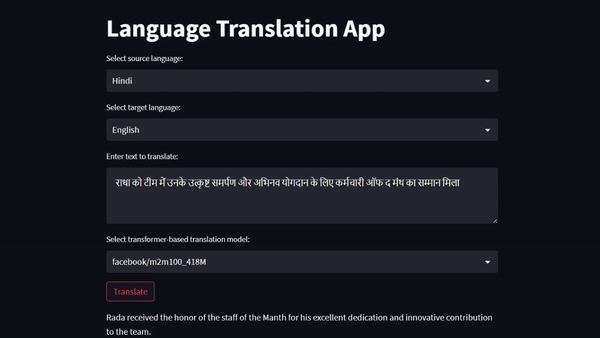
The first work is around building a vanilla Transformer from scratch and training it on iitb-english-hindi's sub-set of test dataset for the task of Machine Translation. Got a BLEU score of 0.61, Character Error Rate of 0.16, Word Error Rate of 0.35, Train loss of 1.50 and Val loss of 1.53. The second work is around building a Machine Translation web app using SoTA Encoder-Decoder-based Pre-trained Language Models for gaining hands-on experience working with LMs on a real case at the production level.
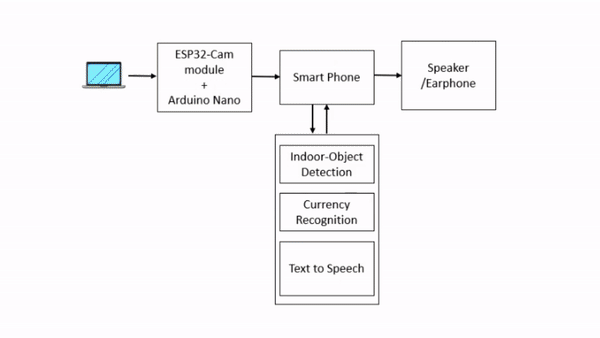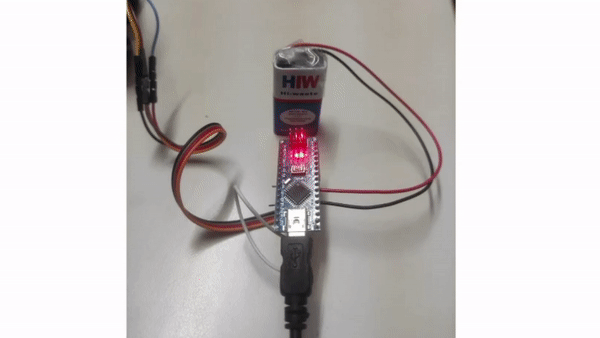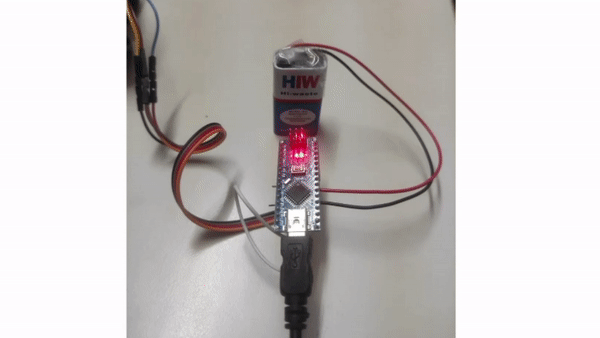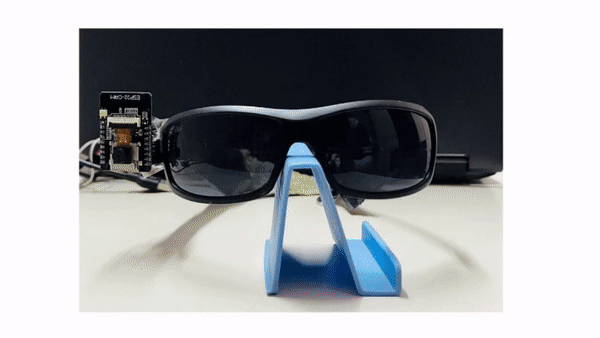
Drishti: Visual Navigation Assistant for Visually Impaired
Started in Sept 2022 | Paper | Project Report
Tech: Computer Vision, Text-to-Speech, Google Cloud Platform (GCP), Python, TensorFlow, Electronics Design and Integrations, Microcontroller Programming
Despite the development of numerous assistive devices over the years, due to various limitations, numerous visually impaired individuals in India still don’t have a navigational assistive tool/device. After reviewing related literature, informal discussions with visually impaired individuals, and a formal survey conducted at Raghuveer Singh Memorial Blind Trust in Shahdara (Delhi), my comprehension of this problem significantly improved. To address it, I developed an initial-stage low-cost eye-wear assistive device and conducted a test with a group of visually impaired participants. This work started as part of my Final-year College Project, and I am actively working to improve this solution.
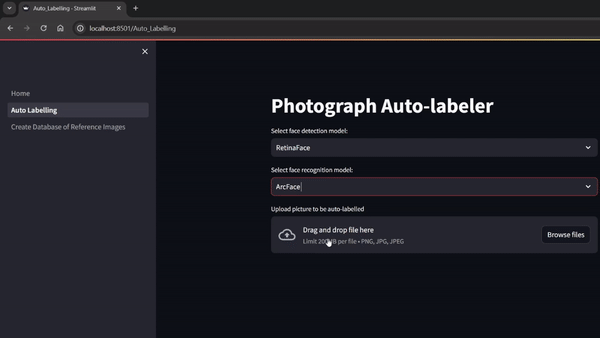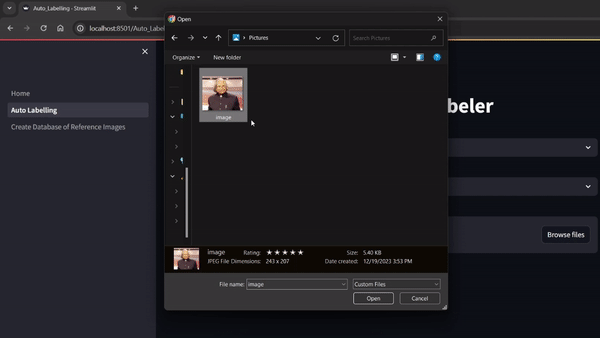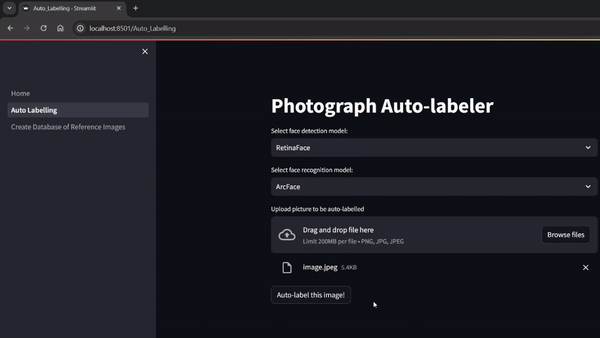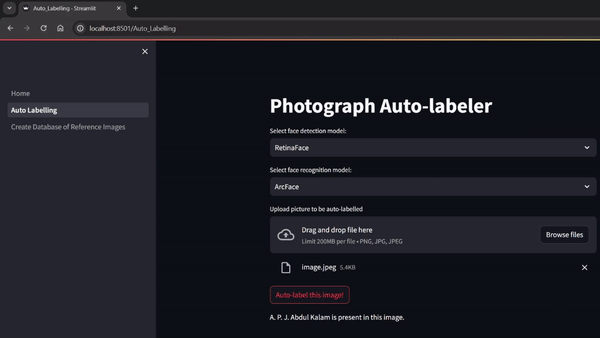
Pehchaan: Person Identifier for Auto-labeling Photographs
Started in July 2022 | Project Page
Tech: Deep Learning, Face detection, Face recognition, Python, Tensorflow, TensorBoard, Streamlit
Manually labelling people in a large stock of photographs is a very time-consuming and labour-intensive and without these labels, these significant photographs are mere pieces of memory/space-consuming items. Pehchaan is a One-shot Labelling tool which attempts to solve this issue by automatically identifying people present in photographs and then labelling their names in those photographs. This system uses pre-trained Face detection model, Face alignment model, Face recognition model and algorithms to keep checking if the database is modified and do one-to-one matching between feature representation of image input by the user and image(s) in the database. This work represents work done as part of my internship at DESIDOC-DRDO (New Delhi, India).

OligoFinder: Bio-NER System to Extract Oligonucleotide Entities
Started in June 2022 | Project Page
Tech: Pre-trained Language Model (BioBERT), Named Entity Recognition, Python, TensorFlow, Google Cloud Platform (GCP), FastAPI
Methods to extract textual references of oligonucleotides have remained limited to being a time-consuming manual process with the inability to generalize to newer variations. OligoFinder is developed as part of the Google Summer of Code'22 program at EMBL-EBI to address these limitations. It is a scalable and semi-automated Bio-NER system for identifying and extracting Oligonucleotide mentions and related data from Biomedical research papers.

TalkingHand: Sign Language Converter
Started in May 2021 | Project Page
Tech: Computer Vision (VGG16 CNN), Transfer-Learning, Image Classification, Python, TensorFlow
TalkingHand is a Computer Vision and Deep Learning-based Sign Language to Text Conversion System that, with the help of fine-tuned VGG16 convolutional neural network, classifies and converts the hand gestures made by the user into corresponding text-based labels. A custom dataset of about 4000 images each for 6 labels has been collected for fine-tuning the CNN model using a combination of background subtraction (MOG2) and colour threshold techniques. These techniques are used so that data collected will have a lower bias due to the shape & colour of the user's hand making the gesture and altering lighting conditions. The model achieved a test Accuracy of 0.802, Precision of 0.805, Recall of 0.801 and F1 score of 0.803. The objective of this project is to take the first step towards developing a solution to help people with speaking and hearing disability communicate with other people.

Describer: Image Captioning System
Started in Apr 2020 | Project Page
Tech: Computer Vision (InceptionV3 CNN), NLP (LSTM), Joint Image-Text Representation Learning, Text Generation, Python, TensorFlow
Describer is an Image Captioning System that generates textual captions describing the images fed to it. It is trained using Flickr8k data. It uses pre-trained InceptionV3 which generates image embeddings and the GloVe's weight initialized Embedding layer which generates captions embeddings. Then, image embeddings after passing through a dense layer and captions embeddings after passing through LSTM, together go to Feed-forward network which outputs next word of input caption. Achieved BLEU-1 score of 0.79 on the test dataset while using Greedy search decoding method. The objective of this project is to take the first step towards developing a solution to help visually impaired people understand visual information around them.
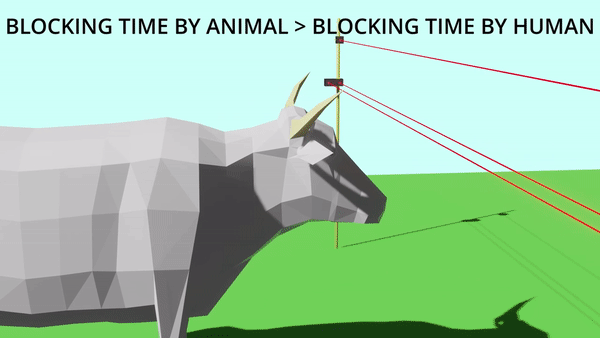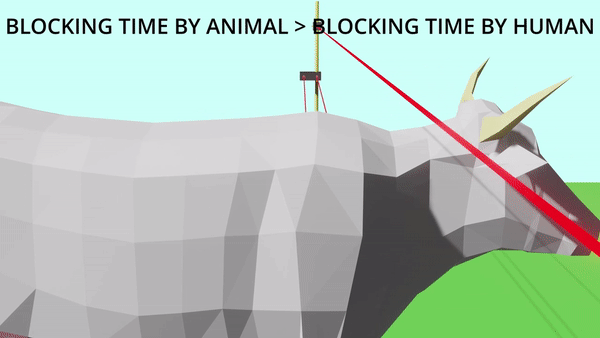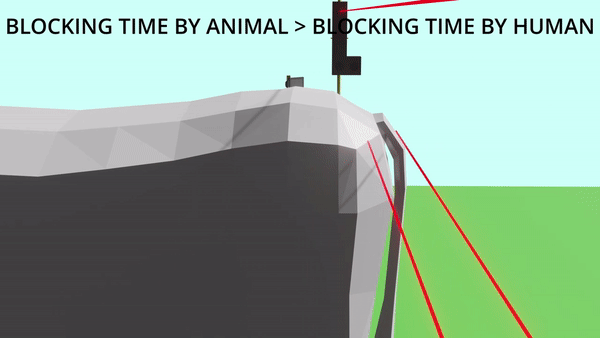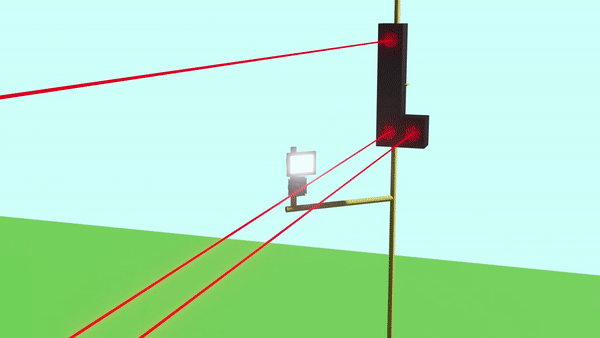
Sanrakshan: Animal Deterrent Device
Tech: Electronics Design and Integrations, Microcontroller Programming, Power Management, Mechanical Design
Farmers of Uttarakhand face the problem of crop destruction by wild animals. To tackle this issue Sanrakshan is developed. It's an animal deterrent device which prevents wild animals from destroying crops by use of "Laser-LDR Detection Technology". This solution works on the principle of using time-of-blocking of laser light reaching the LDR sensor to differentiate between humans and target animals. This work results from extensive involvement in the SIH'2020 competition with two other team members, Abhay Jaiswal and Maitreyi.